日志數(shù)據(jù)是一種廣泛可用的數(shù)據(jù)資源,用于記錄各種軟件系統(tǒng)中運行時的系統(tǒng)狀態(tài)和關(guān)鍵事件。開發(fā)人員通常利用日志數(shù)據(jù)來獲取系統(tǒng)狀態(tài)、檢測異常和定位根本原因。隱藏的豐富信息為分析系統(tǒng)問題提供了一個很好的視角。因此,通過在大量日志數(shù)據(jù)中挖掘日志信息,結(jié)合數(shù)據(jù)驅(qū)動的方法,可以幫助增強系統(tǒng)的健康、穩(wěn)定性和可用性。
01. 日志解析介紹
隨著現(xiàn)代計算機系統(tǒng)規(guī)模和復(fù)雜性的增加,日志數(shù)據(jù)呈爆炸式增長。衍生出了大量數(shù)據(jù)驅(qū)動的方法,以滿足日志自動檢測異常的需求。
1)日志異常檢測流程
在異常檢測之前,需要對日志數(shù)據(jù)進行收集、解析、特征提取等處理。
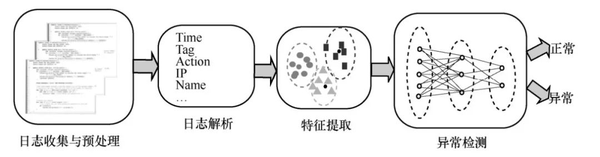
① 日志收集與預(yù)處理
首先需要獲取原始日志數(shù)據(jù)并進行預(yù)處理。日志收集主要指從設(shè)備中獲取相關(guān)日志記錄,包括系統(tǒng)的運行狀態(tài)、時間信息等,這些信息用來記錄系統(tǒng)運行過程中的重要信息,是日志分析的前提。預(yù)處理主要是根據(jù)具體需求,將日志數(shù)據(jù)中的無效信息進行剔除,包括重復(fù)信息、無用信息等。日志信息中的事件序列如圖:

② 日志解析
第二步是日志的解析,對處理后的數(shù)據(jù)進行解析,分析日志結(jié)構(gòu)與信息,獲取日志針對每個事件的模板。日志解析是從無結(jié)構(gòu)的日志中提取相應(yīng)的事件模板,每個模板由多個指定參數(shù)構(gòu)成,作為后續(xù)特征提取的基礎(chǔ)。
③ 特征提取
通過設(shè)定固定的時間范圍作為窗口,對窗口內(nèi)日志內(nèi)容進行解析,提煉其中的事件模板,將日志切分成一組日志事件序列 Log,進而從提取信息中選擇合適的變量和分組來表示相關(guān)內(nèi)容,并進行數(shù)字化向量表示,構(gòu)建成特征向量,方便后續(xù)進行機器學(xué)習(xí)。
實際解析中,可以將不同服務(wù)器的操作進行關(guān)聯(lián)分析,獲得更多的異常信息。例如,針對服務(wù)器 "ZooKeeperServer" 構(gòu)建特征向量<2,1,1, …>,表示事件1 "server environment" 發(fā)生2次,事件 "client attempting to establish new session" 、 "established session" 各發(fā)生 1 次。最終,可以由不同時間段形成的特征向量構(gòu)建成特征矩陣。

其中,日志數(shù)據(jù)的解析是后續(xù)異常分析的重要基礎(chǔ)。
2)日志數(shù)據(jù)解析方法
日志本身是對一系列系統(tǒng)或應(yīng)用中發(fā)生的事件進行記錄,一個記錄通常代表一個事件發(fā)生的相關(guān)具體內(nèi)容,日志記錄通常包含但不限于事件的時間、源頭、標(biāo)簽、信息等。通過一些機器學(xué)習(xí)的方法可以對其中的詳細(xì)信息進行解析。以下是幾種常見的基于機器學(xué)習(xí)的日志解析技術(shù):
① 基于聚類的數(shù)據(jù)挖掘方法:
主要通過計算對日志進行聚類,進而進行數(shù)據(jù)挖掘,形成事件模板,完成對日志的解析。
② 基于自然語言處理的解析方法:
使用自然語言處理對日志進行解析。首先,將文本劃分為單詞進行標(biāo)記;然后,對單個單詞進行詞干分析、同義詞替換、停用詞刪除等;之后,將單詞列表中的句子轉(zhuǎn)化為矢量表示形式,之后運用一些無監(jiān)督聚類算法進行分類。
③ 文本相似度計算方法:
通過對文本相似度進行計算,合并類似模板,實現(xiàn)快速日志解析,例如:利用最長公共子序列算法(LCS)以流方式解析日志。
02. 日志異常檢測
在完成日志數(shù)據(jù)的解析之后,就需要通過日志異常檢測,來對系統(tǒng)運行情況進行判斷,輔助運維人員進行運維工作。
常見的日志異常檢測方法可以分為有監(jiān)督和無監(jiān)督兩種,如聚類分析、決策樹等。例如,在將日志信息標(biāo)記為正常、 異常后,根據(jù)提取的特征進行聚類分析。首先對各個特征賦予不同權(quán)重;然后將特征向量進行歸一化處理;之后定義特征向量之間的相似性(即距離大小);最后對日志間的相似性進行判斷,定義是否為異常。針對異常檢測結(jié)果,進一步進行人工分析和確認(rèn),結(jié)果可以作為樣本加入數(shù)據(jù)集中,對模型進行修正。
近年來也發(fā)展出了許多基于深度學(xué)習(xí)的方法,如基于LSTM的深度學(xué)習(xí)方法等。通過對特征向量進行學(xué)習(xí),對輸入特征矩陣機器學(xué)習(xí)模型進行訓(xùn)練,從而生成一個異常檢測模型,并使用該模型對新的日志進行檢測。
1)監(jiān)督學(xué)習(xí)方法
一種從標(biāo)記的訓(xùn)練數(shù)據(jù)中得出模型的機器學(xué)習(xí)方法。帶標(biāo)簽的訓(xùn)練數(shù)據(jù)(通過標(biāo)簽指示正常或異常狀態(tài))是監(jiān)督異常檢測的先決條件,訓(xùn)練數(shù)據(jù)標(biāo)簽越多,模型越精確。在基于日志的異常檢測方面使用的機器學(xué)習(xí)方法較為寬泛。例如:LogClass,這種方法首先預(yù)處理設(shè)備日志,并產(chǎn)生詞描述方法的矢量,然后通過機器學(xué)習(xí)方法(例如:SVM)來訓(xùn)練異常檢測和分類模型,最后進行在線異常檢測。還有一些其他方法,利用一些常見的機器學(xué)習(xí)模型如:邏輯回歸、KNN算法等進行日志異常檢測。
2)無監(jiān)督學(xué)習(xí)方法
無監(jiān)督學(xué)習(xí)方法指沒有任何標(biāo)記的訓(xùn)練數(shù)據(jù)情況下得到模型的機器學(xué)習(xí)方法。常見的無監(jiān)督方法包括各種聚類方法、關(guān)聯(lián)規(guī)則挖掘、基于主成分分析等。
① 聚類方法
方法思想:通過分析日志特點,把日志劃分為不同的分組,組內(nèi)的日志相似度越大越好,組間的日志相似度越小越好。計算日志間相似度,根據(jù)相似度用相應(yīng)的方法把日志分成不同的類,最后提取日志模板。例如,LogCluster和Log2vec是兩種較為典型的異常檢測方法。
LogCluster:
是一種將日志聚類來進行日志問題識別的方法。首先將每個日志序列通過一個向量表示,然后計算兩個日志序列之間的相似度值,并應(yīng)用聚集層次聚類技術(shù)將相似的日志序列分組為聚類。
Log2vec:
是一種基于異構(gòu)圖嵌入的威脅檢測方法。首先,根據(jù)日志條目之間的關(guān)系 將其轉(zhuǎn)換為異構(gòu)圖;然后使用改進圖嵌入方法,可以自動將每個日志描述為一個低維的向量;最后,通過檢測算法,可以將惡意日志和良性日志進行聚類,識別出惡意行為。
② 關(guān)聯(lián)規(guī)則挖掘
例如:通過最長公共子序列(LCS)方法將日志解析為數(shù)組。然后,使用時間關(guān)聯(lián)分析(TCA)將相似事件聚類,找出操作的關(guān)鍵事件。最后,根據(jù)標(biāo)記進行異常檢測。
除此以外還有其他的日志異常檢測方法,如基于主成分分析法(PCA)。
3)深度學(xué)習(xí)方法
利用卷積神經(jīng)網(wǎng)絡(luò)(CNN)的優(yōu)勢,可以有效地提取并行方式中的空間特征,并通過長短期記憶(LSTM)網(wǎng)絡(luò)來捕獲順序關(guān)系。例如:
① DeepLog
是主要使用長短期記憶的神經(jīng)網(wǎng)絡(luò)模型,將系統(tǒng)日志建模為自然語言序列。DeepLog 從正常執(zhí)行中自動學(xué)習(xí)日志模型,并通過該模型, 對正常執(zhí)行下的日志數(shù)據(jù)進行異常檢測。
② SwissLog
該方法主要包括兩個階段,即離線處理階段和在線處理階段。每個階段包括日志解析、句子嵌入、模型訓(xùn)練階段,在線階段還包括異常檢測階段。
- 日志解析部分對歷史日志數(shù)據(jù)進行分詞、字典化和聚類,提取多個模板,這些日志語句與相同的標(biāo)識符聯(lián)系起來構(gòu)建日志序列,然后將日志序列轉(zhuǎn)化為語義信息和時間信息。
- 句子嵌入部分使用BERT模型或Word2Vec模型對句子進行編碼,轉(zhuǎn)化為詞向量。
- 模型訓(xùn)練階段,將這些語義信息和時間信息輸入到神經(jīng)網(wǎng)絡(luò)模型中學(xué)習(xí)正常、異常的日志序列的特征。
除上述方法外,還有基于文本特征建模,基于工作流,基于不變挖掘 (IM)等其他異常檢測方法。
03. 嘉為鯨眼日志中心
日志解析與異常檢測和對日志數(shù)據(jù)價值發(fā)揮至關(guān)重要,企業(yè)通常也需要引入相應(yīng)的工具,構(gòu)建日志管理能力,確保日志數(shù)據(jù)發(fā)揮價值,保障業(yè)務(wù)的平穩(wěn)運行。
嘉為鯨眼日志中心集成了日志智能化聚類、智能化異常分析場景,基于日志異常檢測能力,可以幫助IT人員快速分析日志及識別異常,提升運維效率,為企業(yè)構(gòu)建一站式日志管理平臺,實現(xiàn)從采集至分析全流程統(tǒng)一日志管理,提升日志管理場景效能,提速排障最后一公里。
1)快速掌握日志全貌
千萬日志數(shù)據(jù)聚合成十幾種格式類型,提高信息密度,避免大量時間看重復(fù)數(shù)據(jù)。

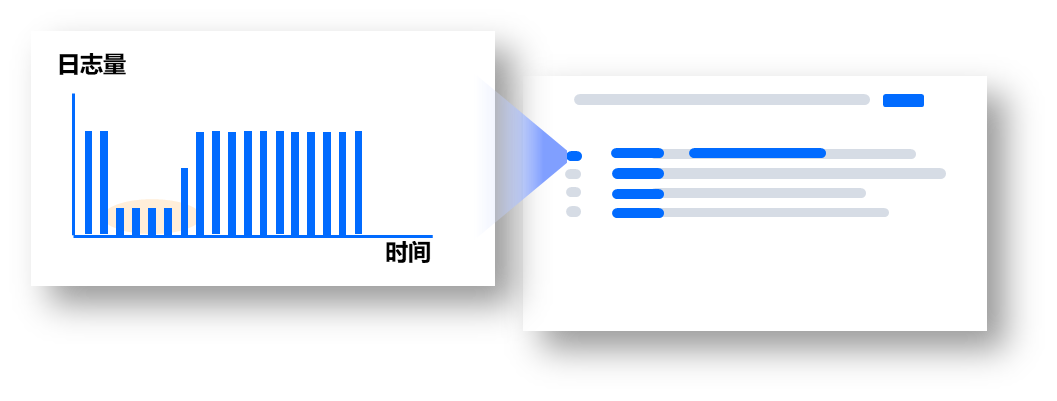
2)敏銳捕捉動態(tài)異常
每種日志格式的日志量變化可視化,迅速清晰地觀察日志異變。
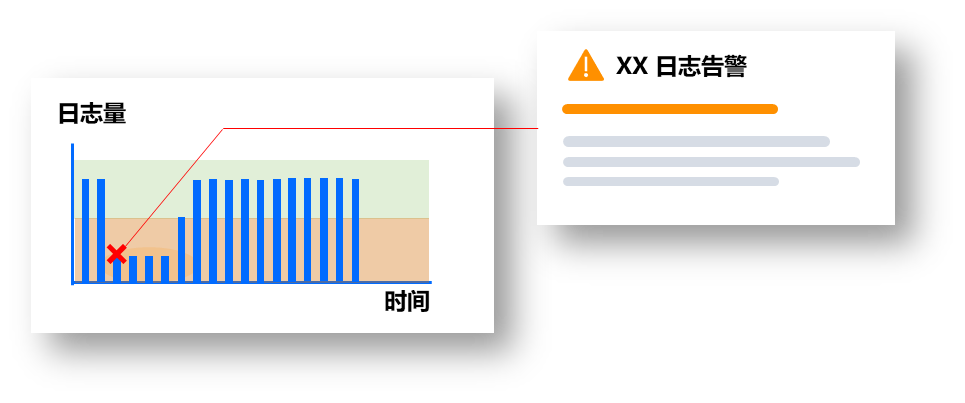
3)動態(tài)配置監(jiān)控策略
無需知曉和人工配置日志異常規(guī)則,自動根據(jù)特定格式的日志量統(tǒng)計來判斷是否異常。
4)輔助定位代碼級別的問題
日志聚類能將代碼運行映射到日志展示,賦予運維通過日志探查故障的鑰匙。

面向企業(yè)IT研發(fā)和運維,滿足分布式架構(gòu)下海量日志采集及存儲、檢索及分析。基于業(yè)界主流的全文檢索引擎,通過藍鯨專屬 Agent 提供多種場景化日志采集,提供快速檢索分析、輔助故障定位功能。產(chǎn)品具備五大優(yōu)勢,為客戶提供日志管理場景價值。
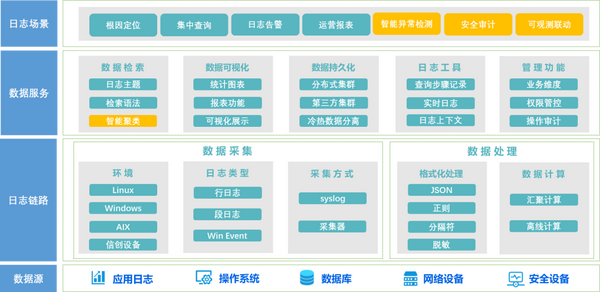
5)方案優(yōu)勢
采集豐富:不同終端不同格式日志統(tǒng)一采集,采集過程中支持解析、脫敏、過濾,采集簡單便捷;
推廣便捷:內(nèi)置常用組件的日志解析模板和儀表盤模板,且允許用戶自建日志解析模板庫,方便接入推廣;
智能高效:融合藍鯨海量數(shù)據(jù)分析底座和智能化組件,實現(xiàn)高效的日志智能聚類,智能異常檢測和告警;
聯(lián)動流暢:和監(jiān)控告警體系打通,快捷配置日志關(guān)鍵字、日志指標(biāo)告警,無需依賴跳轉(zhuǎn);
信創(chuàng)適配:已適配多種國產(chǎn)化設(shè)備和系統(tǒng),也可完成對信創(chuàng)設(shè)備的采集。
6)客戶價值
高效排障:聯(lián)動藍鯨基礎(chǔ)監(jiān)控告警,實現(xiàn)關(guān)鍵字、日志指標(biāo)異常檢測,告警通知,明細(xì)日志下鉆,高效故障定位;
數(shù)據(jù)安全:提供完善的權(quán)限管控、數(shù)據(jù)隔離以及敏感數(shù)據(jù)能保護能力,保障數(shù)據(jù)安全,滿足數(shù)據(jù)安全管理訴求;
成本優(yōu)化:提供數(shù)據(jù)分層架構(gòu),按照冷、熱數(shù)據(jù)分層,合理降低存儲成本;
便捷推廣:結(jié)合藍鯨Agent能力實現(xiàn)日志采集插件一鍵部署、批量安裝、性能穩(wěn)定。
相關(guān)文章推薦
ITSM運營:服務(wù)請求管理持續(xù)改進

 2025-04-11
2025-04-11
查看詳細(xì)


AI驅(qū)動IT運維轉(zhuǎn)型:從審批流到AI工作流
2025-04-11
查看詳細(xì)
國產(chǎn)化替代實踐:嘉為藍鯨全棧智能觀測中心對比IBM Tivoli
2025-04-11
查看詳細(xì)
嘉為藍鯨平臺:三位一體,打造云原生數(shù)字化基座
2025-04-11
查看詳細(xì)
嘉為藍鯨DevOps研發(fā)效能管理平臺:AI賦能研運,效能再進化
2025-04-11
查看詳細(xì)
ITSM運營:事件管理持續(xù)改進
2025-04-07
查看詳細(xì)







